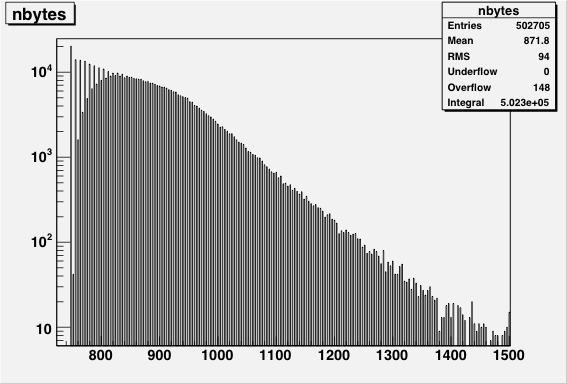
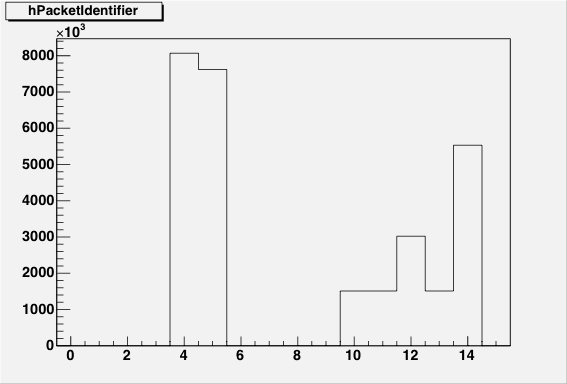
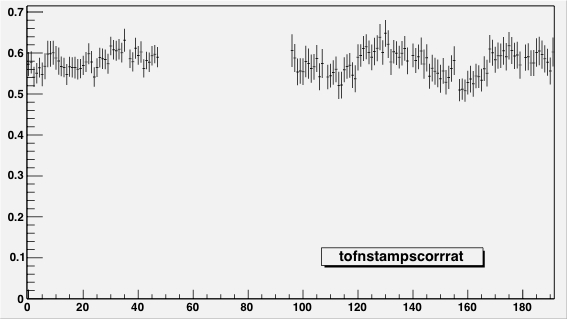
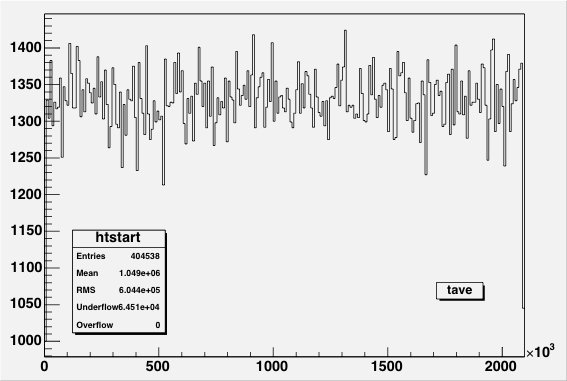
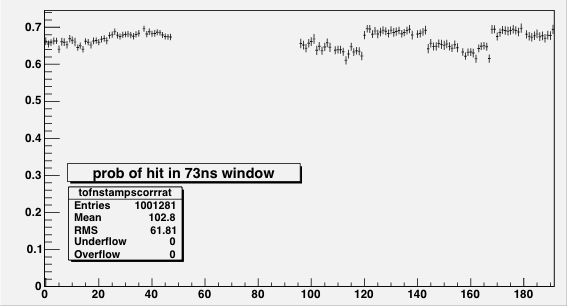
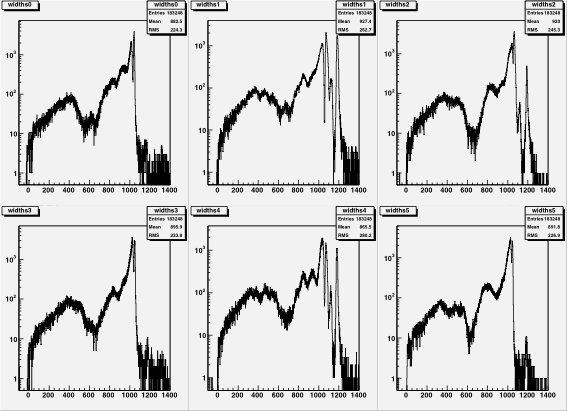
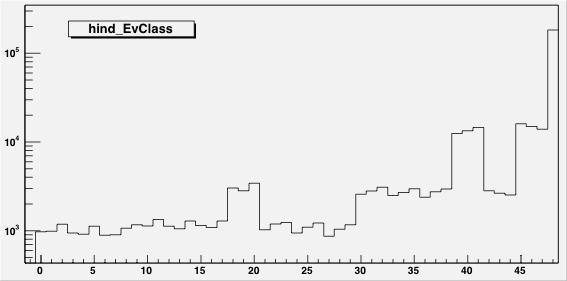
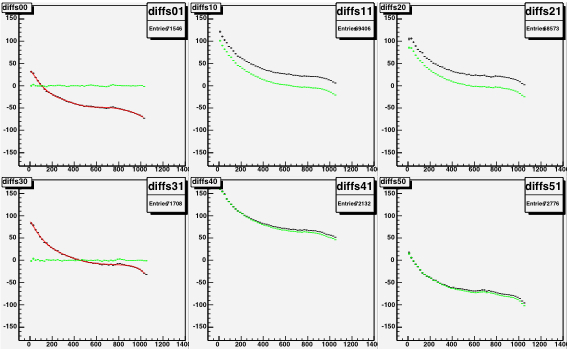
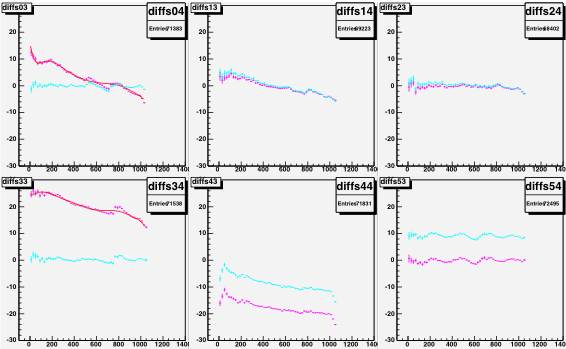
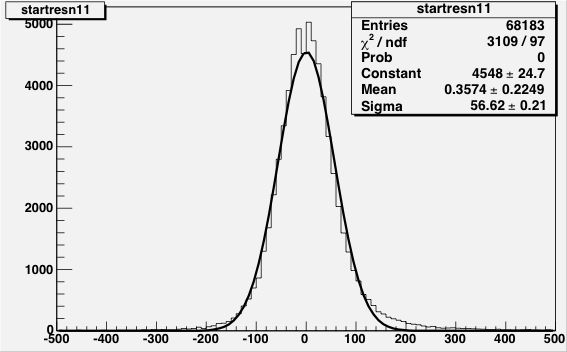
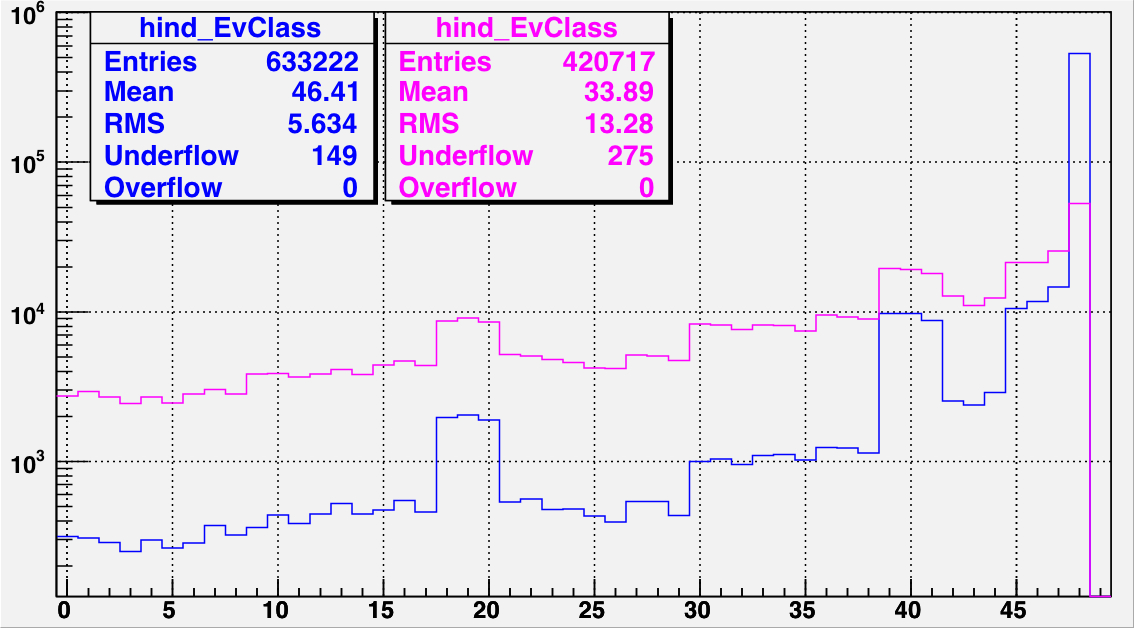
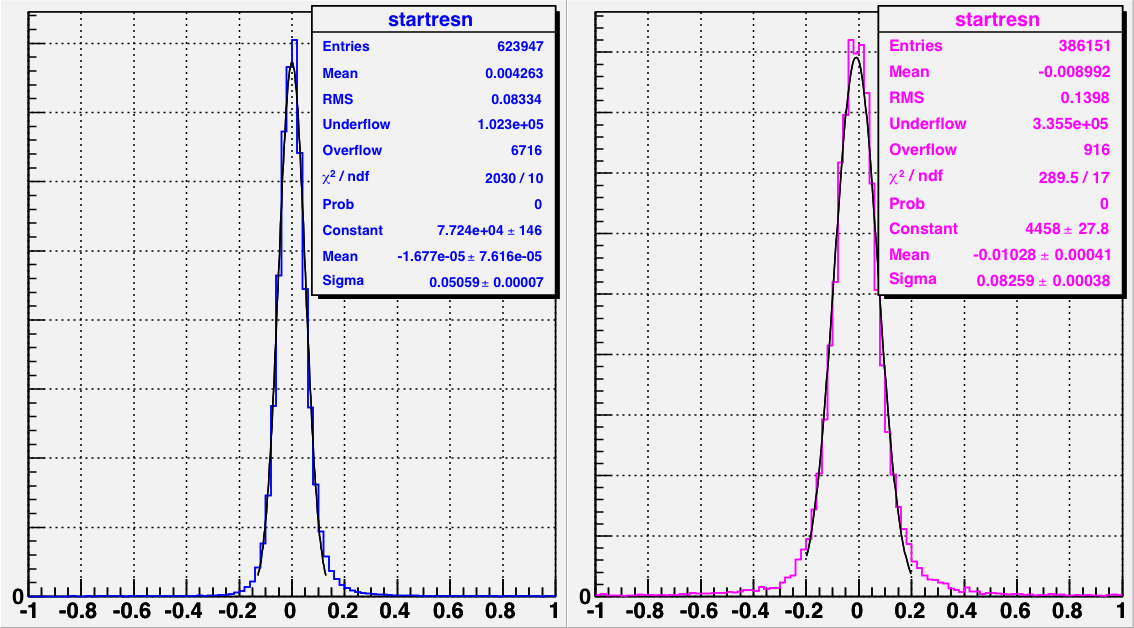
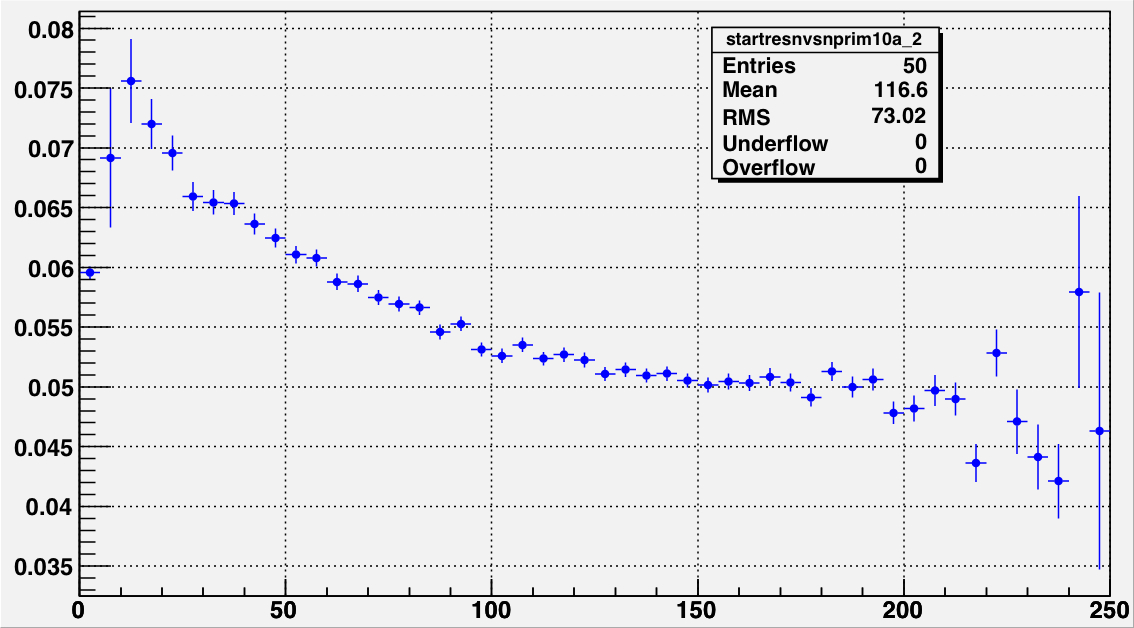
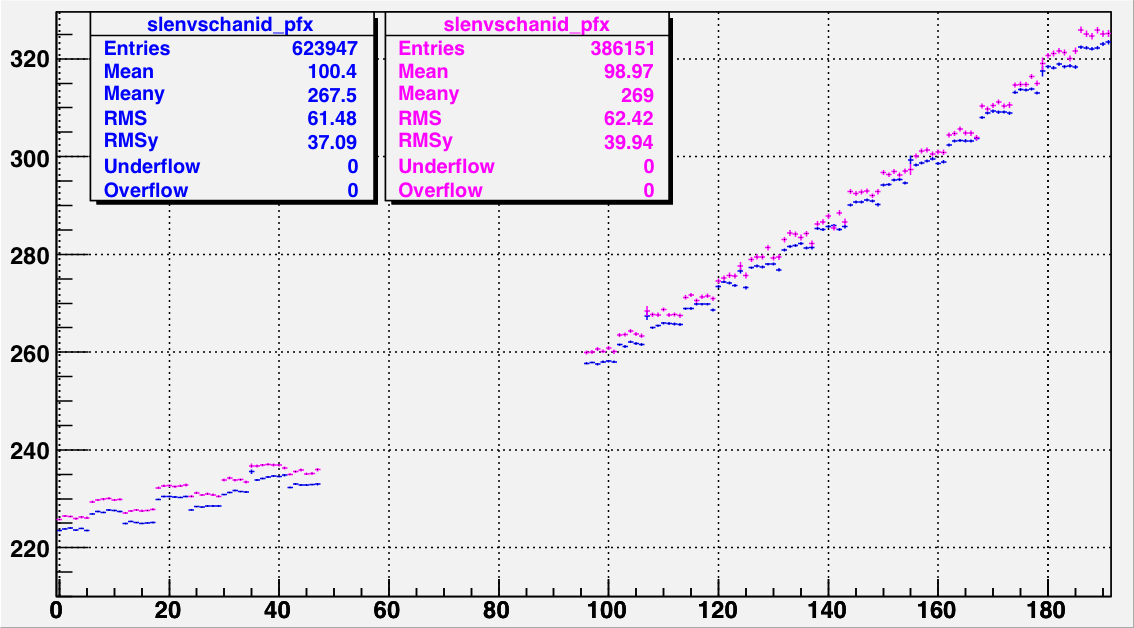
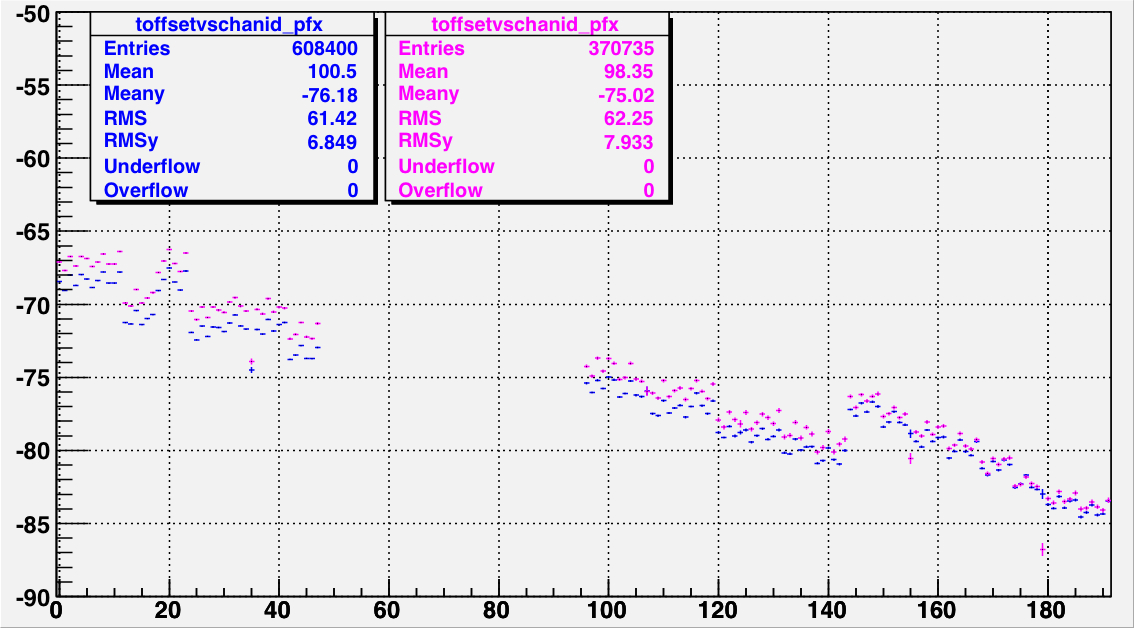
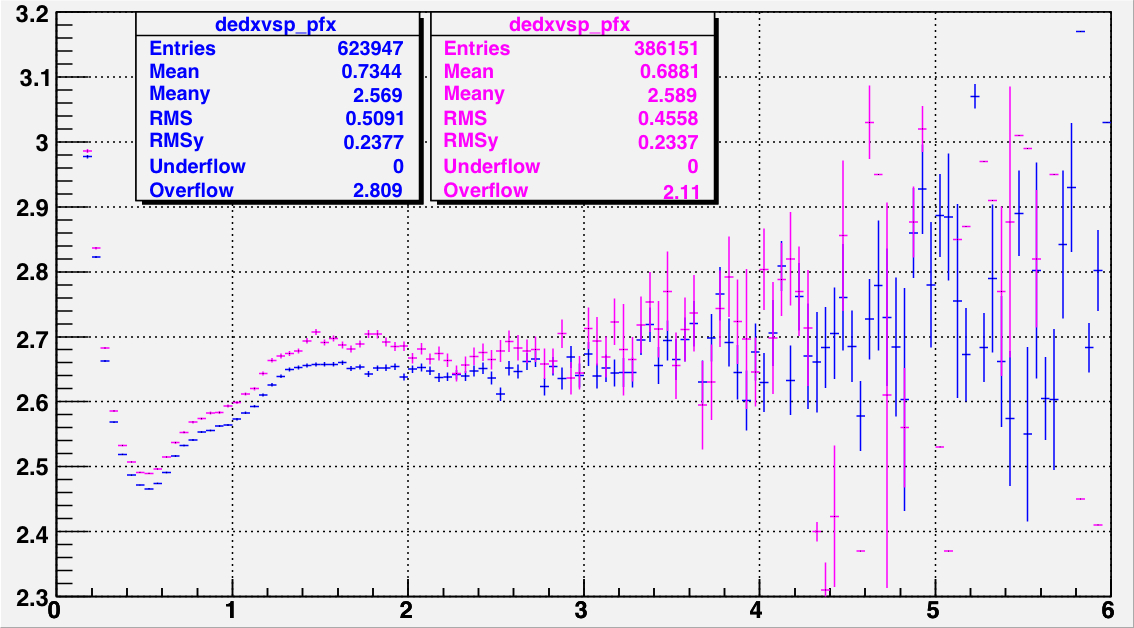
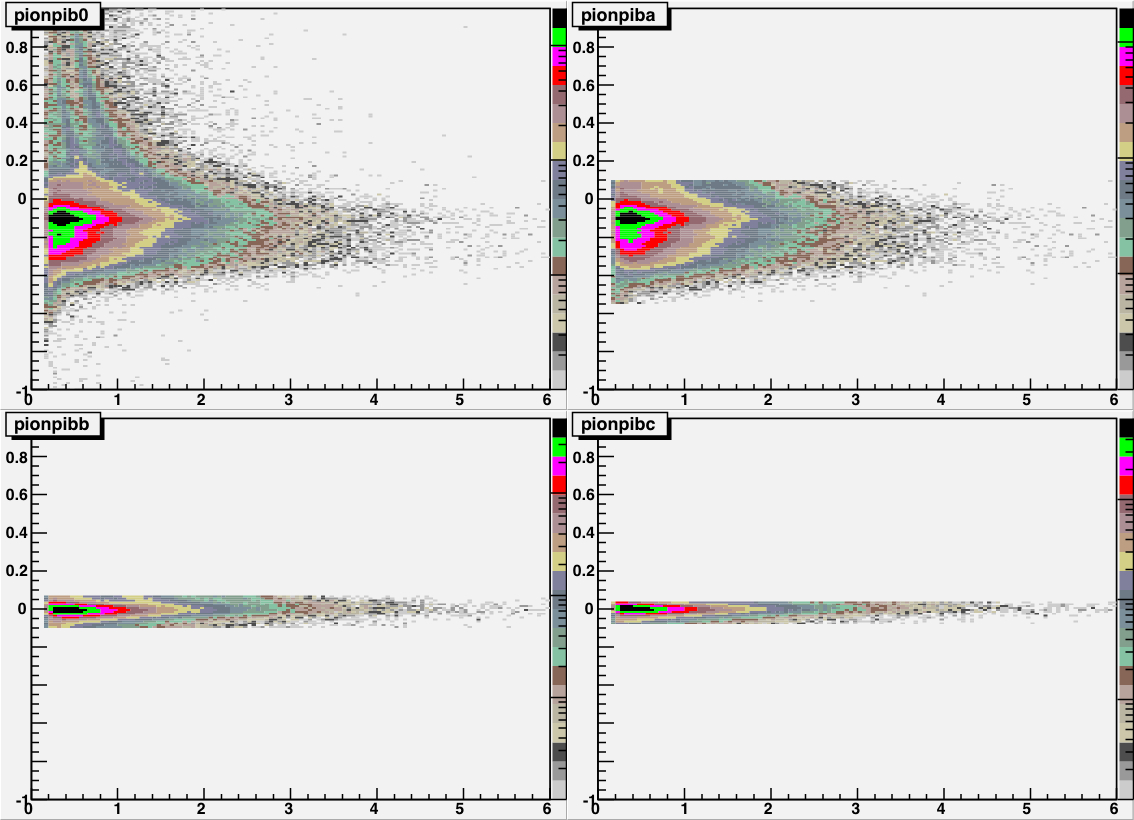
|
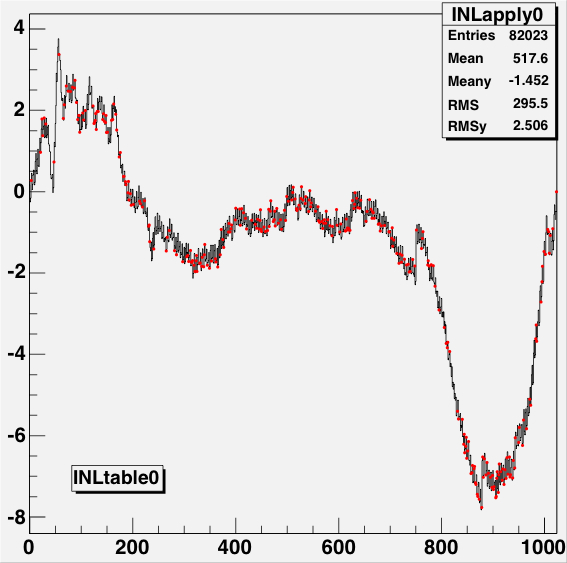
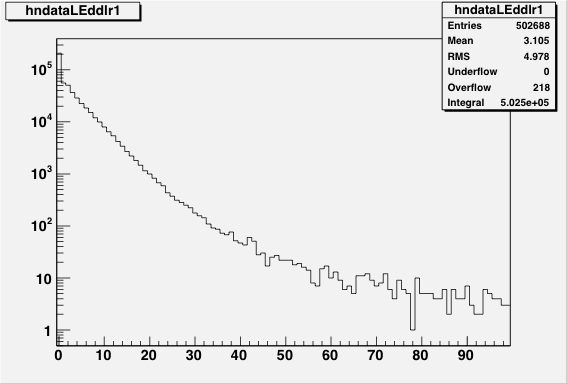
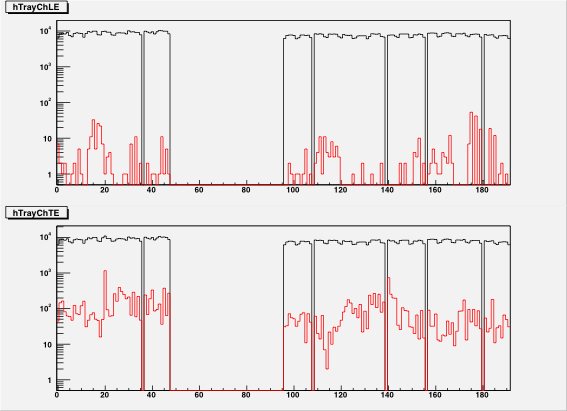
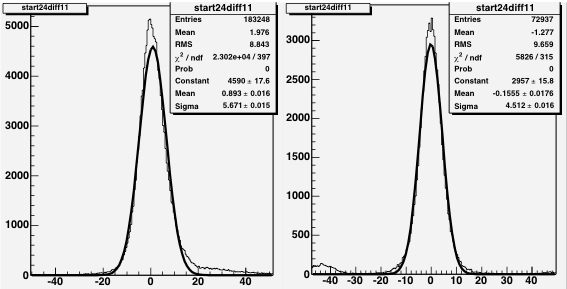
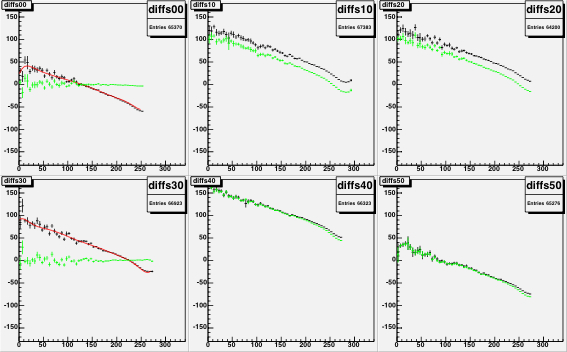
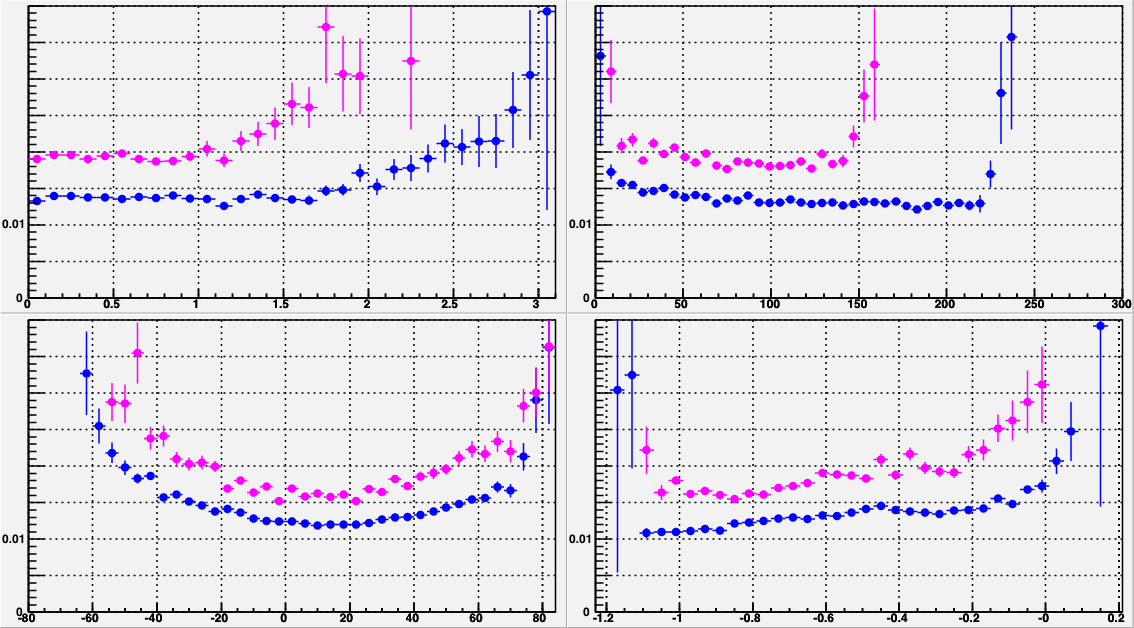
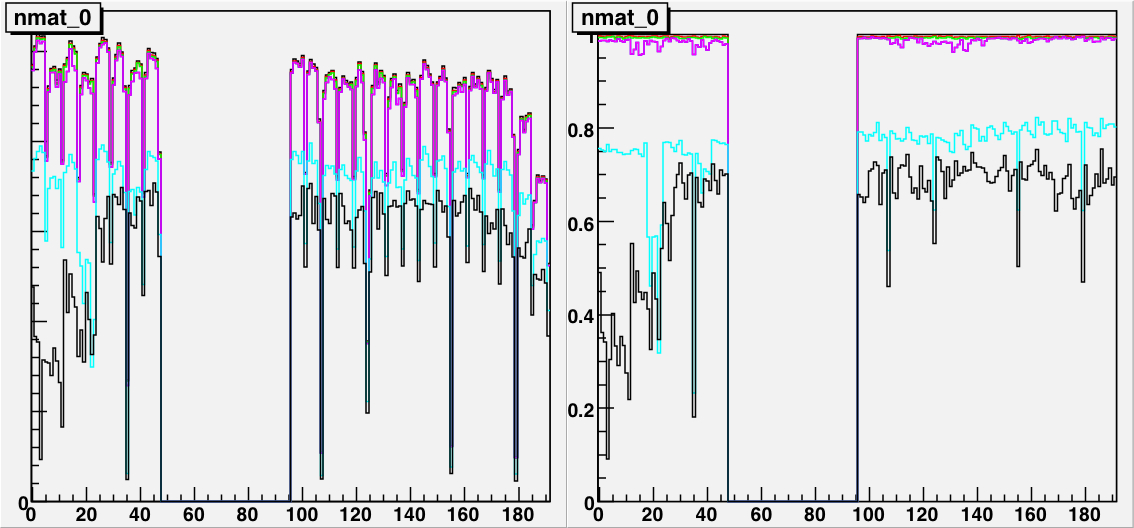
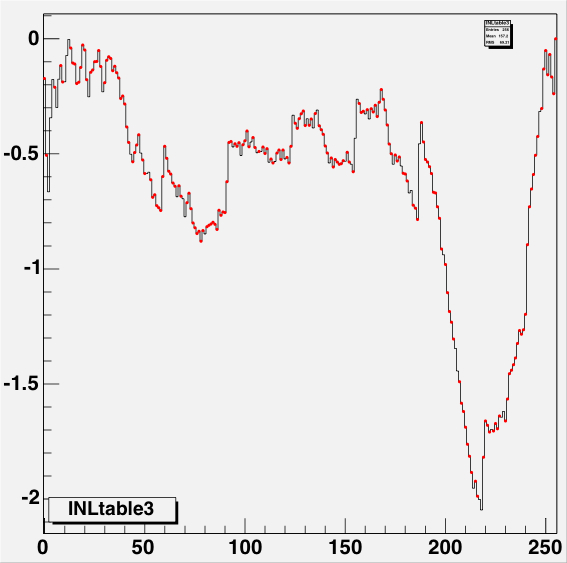 Figure 13: The INL corrections for a LE TDC (HPTDC=0) on the left, and
for a TE TDC (HPTDC=3) on the right, versus the INL bin number.
The black histogram is the table as read from the files, and
the red points are the table as applied to the data during
the event processing.
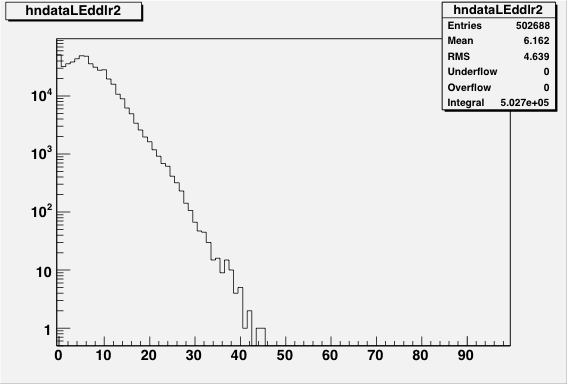
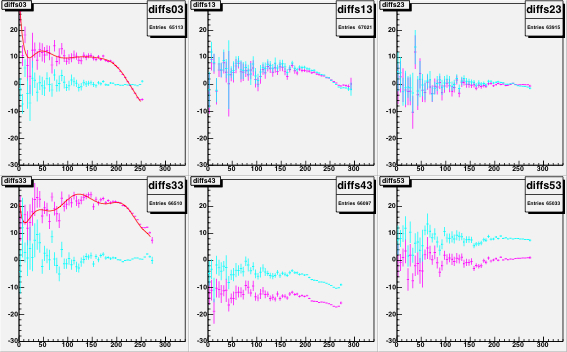
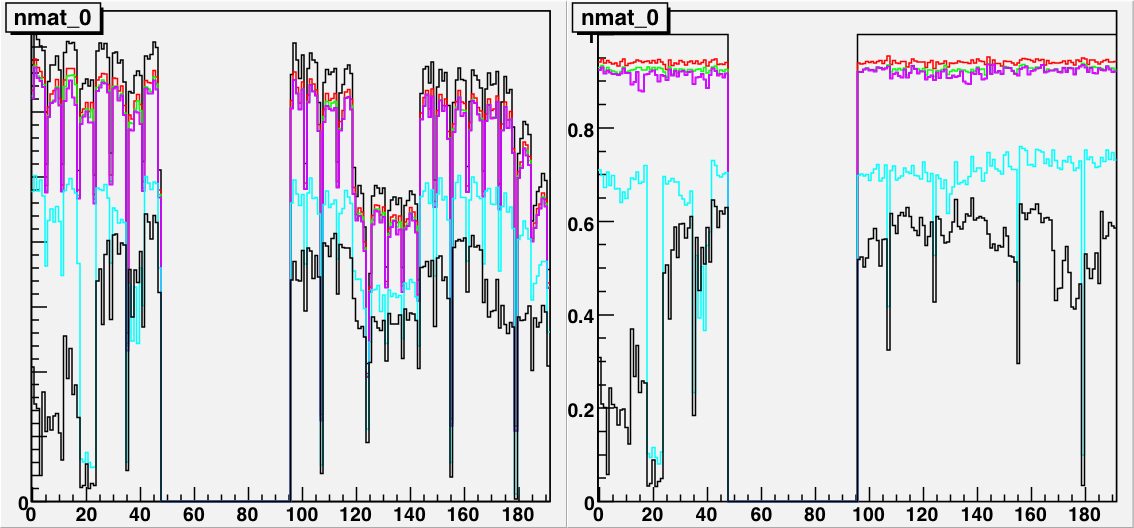
Figure 13: The INL corrections for a LE TDC (HPTDC=0) on the left, and
for a TE TDC (HPTDC=3) on the right, versus the INL bin number.
The black histogram is the table as read from the files, and
the red points are the table as applied to the data during
the event processing.
|
| |